# 富文本编辑器从伤感到破局
# 伤感
浏览器提供了 contenteditable 使得元素可以编辑,以及 document.execCommand 让 js 具备能力去改变元素。但直接用这两个能力去做富文本编辑器是很坑的:参考文章
- 什么是contentEditable MDN解释
- contentEditable实际上是浏览器厂商提供的一个富文本编辑器的实现方案。通过设置一个dom的contenteditable属性为true,可以让这个DOM变得可以编辑。
- 什么是document.execCommand MDN解释
- 当一段document被转为designMode(contentEditable 和 input框)的时候,document.execCommand的command会作用于光标选区(加粗,斜体等操作),也可能会插入一个新的元素,也可能会影响当前行的内容,取决于command是啥。
- 坑
- 不可预测的表现:比如标签被吃了,出现多余的标签
- 行内标签嵌套,ab和ba是一样的
- ...
ContentEditable 是一种在web浏览器上进行富文本编辑的本地原生组件. 它是那样让人…伤感.
# 破局
我们知道React和Vue都有虚拟dom,那么这里差不多是一样的 操作一个简单的JS对象一定是比操作DOM要简单的,这屏蔽了浏览器差异,规避了DOM复杂的特性。
# State
首先,我们在View和command之间引入一个state。在数据存储层面,我们就不需要维护复杂的DOM结构了,可以用一个JS object的结构去维护当前结构
const state = [{
type: 'p',
style: '',
children: []
}]
OK,可以看到这是一个树状的结构,那么针对下面这种结构
<p>
text <span>span text</span>
</p>
在我们的Editor State中怎么表示呢?我们需要修改以下上边的那个状态
const state = [{
type: 'p',
style: '',
children: [
{ type: 'textNode', style: '', content: 'text '},
{ type: 'span', style: '', children: [
{type: 'textNode', style: '', content: 'span text'}
]}
]
}]
- 还是有问题
- ui没变state一直在变,比如
<p>
text <strong>strong</strong><strong><em>italic text</em></strong>
</p>
<p>
text <strong>strong</strong><em><strong>italic text</strong></em>
</p>
- 这两个ui是一样的,但是state却在发生变化
- 这样的树状的结构导致我们操作跨层级的DOM十分不方便(更新这个state的时候更困难,确定边界困难)
# 如何让行内标签不影响dom结构呢?
- 我们实际上是可以把他作为style处理的,比如 strong 我们可以等价于 font-weight: bold, em 可以等价于 font-style: italic。
- 让我们加一个叫marks的属性来表示这些修饰用的行内标签。
const state = [{
type: 'p',
style: '',
marks: [],
children: [
{ type: 'textNode', style: '', content: 'text '},
{ type: 'textNode', style: '', marks: ['strong'], content: 'strong'},
{ type: 'textNode', style: '', marks: ['strong','em'], content: 'italic text'}
]
}]
- 继续,可以看到我们上面还写了style,表示我们的标签可以有样式,既然如此,我们再扩展一下,加个东西叫attributes,既可以容纳样式,也可以容纳类,id,dataset等一系列东西。
const state = [{
type: 'p',
attrs: {},
children: [
{ type: 'textNode', attrs: {}, content: 'text '},
{ type: 'textNode', attrs: {}, marks: ['strong'], content: 'strong'},
{ type: 'textNode', attrs: {}, marks: ['strong','em'], content: 'italic text'}
]
}]
# strong和em也有样式,怎么办?
const NodeAndMarkGen = (nodeType, attrs) => {
return {
type: nodeType,
attrs: attrs
}
}
const paragraph = NodeAndMarkGen('p', {})
const textNode = NodeAndMarkGen('textNode', {})
const strong = NodeAndMarkGen('strong', {})
const em = NodeAndMarkGen('em', {})
const state = [{
...p
children: [
{...textNode, content: 'text '},
{...textNode, marks: [strong], content: 'strong'},
{...textNode, marks: [strong, em], content: 'italic text'},
]
}]
到这里,我们就解决了一下如何存储编辑器状态的问题,结构清晰易懂。但是实际上还没有解决任何真正的问题,比如上面说的回车啊,标签嵌套混乱。
# ProseMirror
# 代码结构
- prosemirror核心有四个模块
- prosemirror-model:定义编辑器的文档模型,用来描述编辑器内容的数据结构
- prosemirror-state:描述编辑器整体状态,包括文档数据,选择等
- prosemirror-view:UI组件,用于将编辑器状态展现为可编辑的元素,处理用户交互
- prosemirror-transform:修改文档的事务方法
- 下面我们就从state,view,transform三个方面来探索prosemirror的实现原理
# 典型流程
# 初始化流程
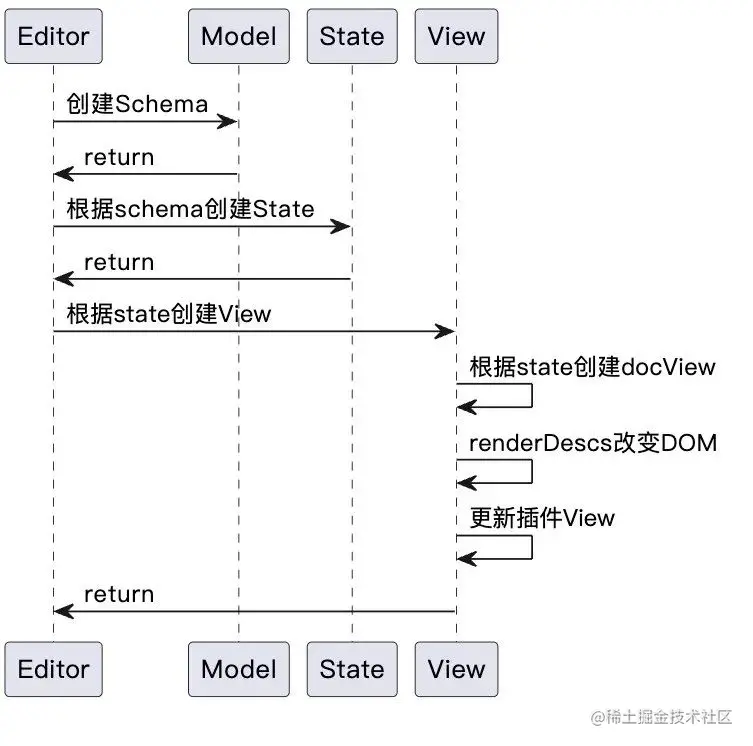
- 首先看一下prosemirror的初始化代码
// 创建schema
const demoSchema = new Schema({
nodes: addListNodes(schema.spec.nodes, "paragraph block*", "block"),
marks: schema.spec.marks
})
// 创建state
let state = EditorState.create({
doc: DOMParser.fromSchema(demoSchema).parse(document.querySelector("#content")),
plugins: exampleSetup({ schema: demoSchema })
})
// 创建view
let view = EditorView(document.querySelector('.full'), { state })
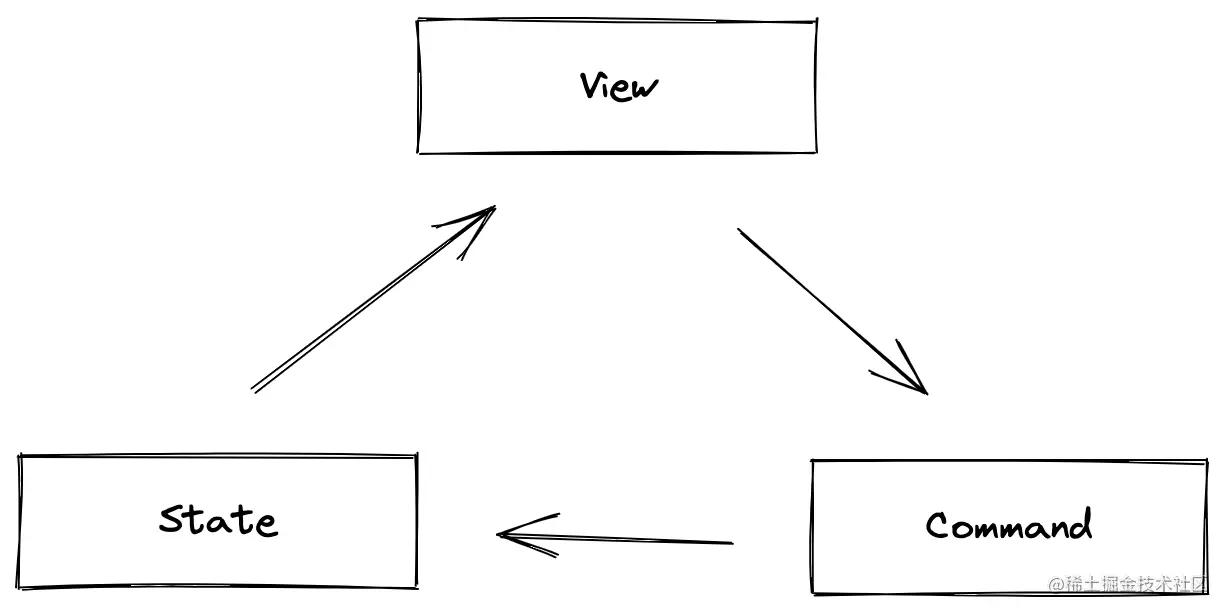
初始化的代码非常清晰,先是创建文档数据的规范标准,类似约定了数据协议。其次创建了 state,state 是需要满足 schema 规范的。最后根据 state 创建了 view,view 就是最终展现在用户面前的富文本编辑器UI。因为初始化的时候还没有用户操作的介入,所以并不涉及 command 也就是 transform 的引入。
- 因为此类架构的富文本编辑器本质是 F(state) = view ,界面是由数据驱动的
- 而 contenteditable 的元素又是非受控的,所以保证状态和界面的一致性是非常重要的。
- 是不是很快就想到了React中的input组件在受控和非受控下的差异
- 非受控的时候我们是通过ref来改变的
# 更新流程
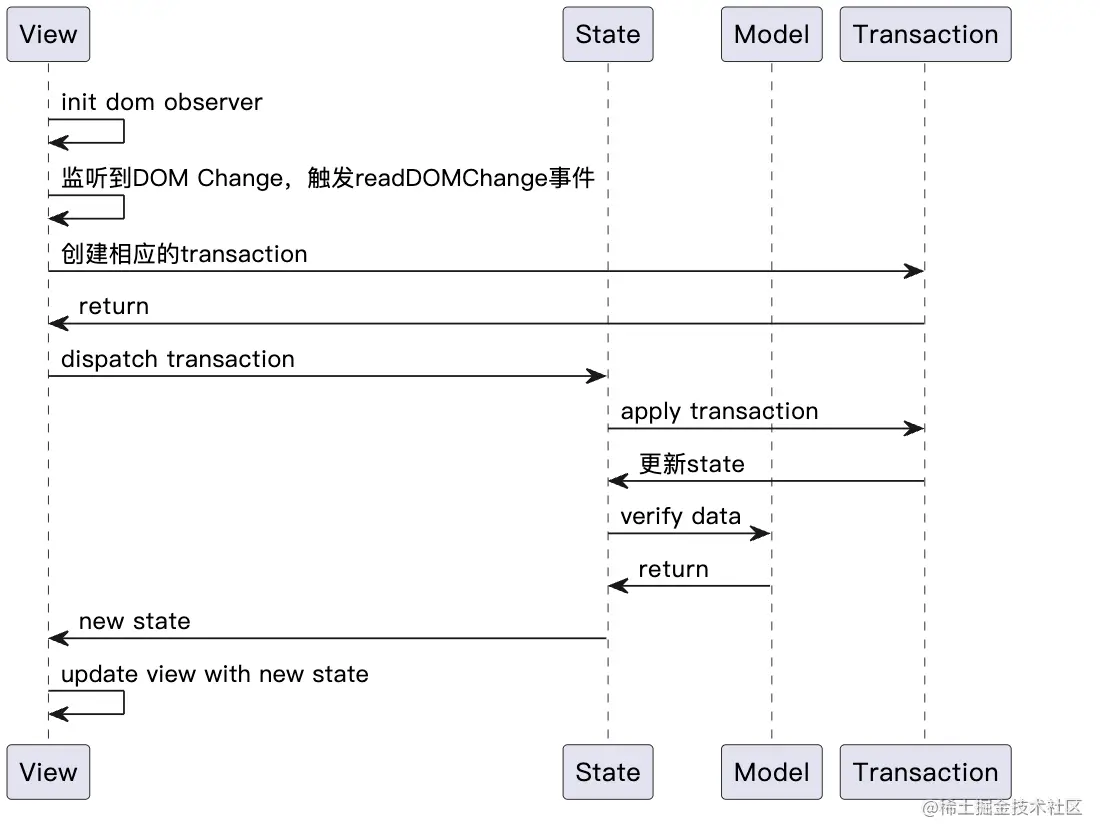
- 可以看到输入字符会触发 view 变化,继而更新 state ,保证 state 和 view 的一致性。如果我们输入的是自定义的元素,就会在触发 state 更新之后,再通过 updateState 方法更新 view,展示自定义的元素。
# State层
- prosemirror 的 state 并不是固定的,而是可以扩展的,但其有基本的四个属性:
- doc(最核心)
- 在初始化流程中,DOMParser 会把初始富文本信息同步到 doc 属性中。
- selection
- storedMarks
- scrollToSelection
- doc(最核心)
每一次编辑都会产生一份新的编辑器数据,如何优化存储,也是比较有意思的话题,不在本文描述。
另外值得提一嘴的是,其 plugin 机制也是基于 state 来做的。
# 文档结构
众所周知,HTML的文档结构是树状的,而 prosemirror 采用的是基于 inline + mark 的数据结构。 每个文档就是一个 node , node 包含一个 fragment ,fragment 包含一个或者多个子 node 。其中核心是 node 的数据结构。

这个在破局里面其实已经提到过了!
- 这种inline,mark的写法可以保证文档的稳定性
- 除了上述这个优点以外,针对富文本编辑这个场景,这种数据结构还有其他的优势。
- 更符合用户对文本操作的直观感受,可以通过偏移量来描述位置,更加轻易的做分割。
- 通过偏移量来操作性能上会比操作树要好很多。
# view层
view 调用 updateState (也就是根据 state 来更新视图, 在更新流程中有提到)时,会调用节点的 toDOM 方法来创建 DOM 元素,从而渲染到浏览器上。
相应的还有 parseDOM 方法,可以根据 DOM 元素,序列化成文档数据。
每次初始化,或者有 state 有更新的时候,都会触发 updateState 方法,从而完成界面的更新。
# transform层
在更新流程中,当 view 发生变化时,会构建 transaction (其父类就是 transform),来更新 state。
通过该堆栈可以发现,在富文本编辑器输入内容的时候,会触发 DOM 变更事件,进而通过 view.state.tr.insertText 来创建一个 insertText 的 transaction。一个 transaction 内部有一个或者多个 step ,insertText 这个 transaction 内部只有一个 ReplaceStep。
prosemirror 内置的 Step 包括:
- AddMarkStep
- RemoveMarkStep
- ReplaceStep
- ReplaceAroundStep 这些 step 都有核心的两个方法,一个是 apply ,另外一个是 invert 。apply 就是运行这个 step , invert 就是恢复用的动作。这对于做回退操作是非常有用的。
← 写在前面 Bootcamp学习笔记 →